
BLOGS Y ACTUALIZACIONES
Estadística aplicada al campo: Construyendo modelos que entiendan tu producto
MARZO 12, 2026
La precisión de un modelo predictivo no depende solo de la tecnología, sino de la calidad y representatividad de los datos con los que se construye. En agroindustria, entender la variabilidad del producto es la clave para obtener mediciones fiables en la línea de producción.
La variabilidad: el gran reto de la agroindustria
En la agroindustria, la única constante es la variabilidad. Factores como la climatología, el estrés hídrico, el momento de recolección o la variedad del fruto hacen que no existan dos campañas —ni siquiera dos lotes— exactamente iguales.
Ante esta realidad, las plantas de procesado y las almazaras necesitan anticiparse. Para ello, es imprescindible medir parámetros clave de la materia prima en continuo, permitiendo optimizar el rendimiento industrial y clasificar adecuadamente el producto desde el primer momento.
Sin embargo, aquí aparece uno de los mayores retos técnicos del sector: la pérdida de fiabilidad de los modelos de predicción cuando se enfrentan a la realidad de la fábrica. Un modelo matemático o de calibración puede funcionar perfectamente en un entorno controlado, pero fallar cuando se aplica directamente en la línea de producción.
El motivo suele estar en un sesgo en la información base. Si el sistema no se construye sobre una distribución de datos de entrada realmente representativa —que contemple toda la variabilidad y las anomalías propias del campo— las predicciones pierden precisión, comprometiendo decisiones que impactan directamente en la rentabilidad del proceso.
Cómo se construye un modelo predictivo fiable
La creación de un modelo predictivo robusto no es cuestión de intuición, sino de estadística y rigor metodológico.
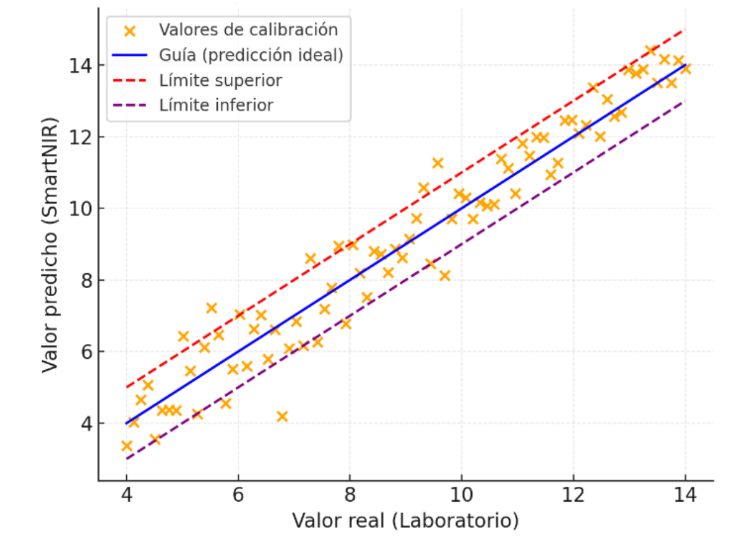
Todo comienza en la fase de calibración, donde se establece una relación matemática entre la señal física capturada por el sensor en la línea de producción —por ejemplo, la absorción de luz en tecnologías espectroscópicas como el NIR (Near Infrared)— y los valores reales de la muestra, obtenidos mediante análisis de laboratorio estandarizados.
El verdadero secreto está en la distribución de los datos utilizados para construir el modelo. Si se emplean únicamente muestras ideales, promedios o datos de una única fase de la campaña, el sistema desarrolla lo que podríamos llamar una miopía estadística: será incapaz de interpretar correctamente frutos con características atípicas, como un contenido de humedad elevado, una maduración diferente o un rendimiento graso fuera de lo habitual.
Una base de datos de calibración sólida debe abarcar el rango completo de la variabilidad natural e industrial. Esto implica incluir muestras que representen distintos orígenes, variedades, estados de madurez y condiciones de cultivo.
Desde el punto de vista estadístico, esto significa que la curva de calibración debe estar poblada de forma equilibrada a lo largo de todo su espectro, evitando concentrar la mayoría de los puntos en valores medios y dejando los extremos infrarepresentados.
Cuando el modelo se alimenta con una matriz de datos rica, diversa y bien balanceada, el error de predicción se reduce significativamente y el sistema mantiene su precisión incluso ante fluctuaciones inesperadas del producto. En definitiva, la fiabilidad de la medición en la fábrica será siempre un reflejo directo de la calidad y representatividad de los datos con los que se calibró el sistema.
El enfoque de ISR: modelos que se adaptan a cada planta
En ISR somos plenamente conscientes de que cada planta de procesado tiene sus propias particularidades y que las calibraciones genéricas rara vez soportan la realidad de una campaña agrícola.
Por ello, nuestro enfoque con tecnologías como SmartNIR no se basa en imponer modelos cerrados, sino en ajustarnos al máximo a las necesidades reales de cada almazara.
Sabemos que la fiabilidad de una predicción depende en gran medida de que el equipo trabaje bajo condiciones similares a las de su entorno operativo diario. Por eso, más que ofrecer soluciones estándar, trabajamos en adaptar el sistema a las instalaciones, al flujo de proceso y a las condiciones de trabajo específicas de cada cliente.
Este esfuerzo de personalización en la toma y selección de datos nos permite construir modelos matemáticos que realmente entienden la variabilidad propia de cada producto y cada campaña.
El resultado es una herramienta capaz de transformar esa complejidad natural en mediciones fiables y útiles para la toma de decisiones en tiempo real dentro de la fábrica.
Datos fiables para decisiones rentables
El éxito de la predicción en la agroindustria no depende de algoritmos mágicos, sino de construir modelos matemáticos basados en datos que reflejen fielmente la variabilidad del campo y de la fábrica.
La clave está en evitar soluciones estandarizadas que no resisten el ritmo de la campaña y apostar por tecnologías que se integren de forma natural en la realidad operativa de cada instalación.
Porque al final, adaptar la tecnología al producto y al proceso de cada almazara es la única manera de garantizar mediciones fiables, optimizar los procesos en tiempo real y proteger la rentabilidad del productor frente a la incertidumbre.

